Accelerating Inference: How Brium is Shaping the Future of AI across GPU Architectures
![]()
Introduction
At Brium, We’re dedicated to enabling ML applications on a diverse set of architectures and unlocking the hardware capabilities through engineering choices, made at every level of stack — from model inference systems, through runtime systems and ML frameworks, to compilers.
In recent years, the hardware industry has made strides towards providing viable alternatives to NVIDIA hardware for server-side inference to address exponentially growing demand for computing power. Today, a lot of hardware, such as AMD’s Instinct GPUs, offer strong performance characteristics, but it remains a challenge to harness that performance in practice. At Brium, we intend to enable efficient LLM inference on any hardware.
On the software side, Long-context Large Language Model (LLM) inference has become crucial for applications ranging from video understanding to retrieval-augmented generation, code assistance and even novel chain-of-thought approaches that enhance model accuracy.
In this post we’ll compare Brium’s inference platform with popular inference serving solutions such as VLLM and SGLang on AMD’s MI210 and MI300 series and show how Brium’s stack can translate to improved throughput as well as improved latency. As usual with inference, shorter latency will increase application responsiveness, higher throughput will likely decrease the total cost of ownership (TCO) of an inference system, and a combination of both may unlock new AI applications.
Showcasing Real-World Performance
Here’s an example where we prompt Llama 3.1-8B to come up with novel verses in Shakespearean style by providing a large context (128k tokens) of similar work.
On the left, the inference is running through our stack, and on the right, we’re running SGLang. You can easily spot the difference in responsiveness! We finish serving the request in less than half the time on MI210 producing identical output.
Brium Inference on MI210 generating tokens:

Comparison of Inference Times:
- Brium
- TTFT: 1m23s
- Total Time: 3m12s
- SGLang
- TTFT: 2m26s
- Total Time: 7m50s
Benchmarking
The Brium team has been working on pushing the boundaries of long context LLM performance on AMD Instinct hardware, optimizing every layer of the inference stack.
For short sequences, Brium’s platform is on par or slightly better than the best of the alternatives. As the sequence length increases, our advantage stands out on both Time To First Token and throughput. This advantage increases on more capable hardware such as MI300.
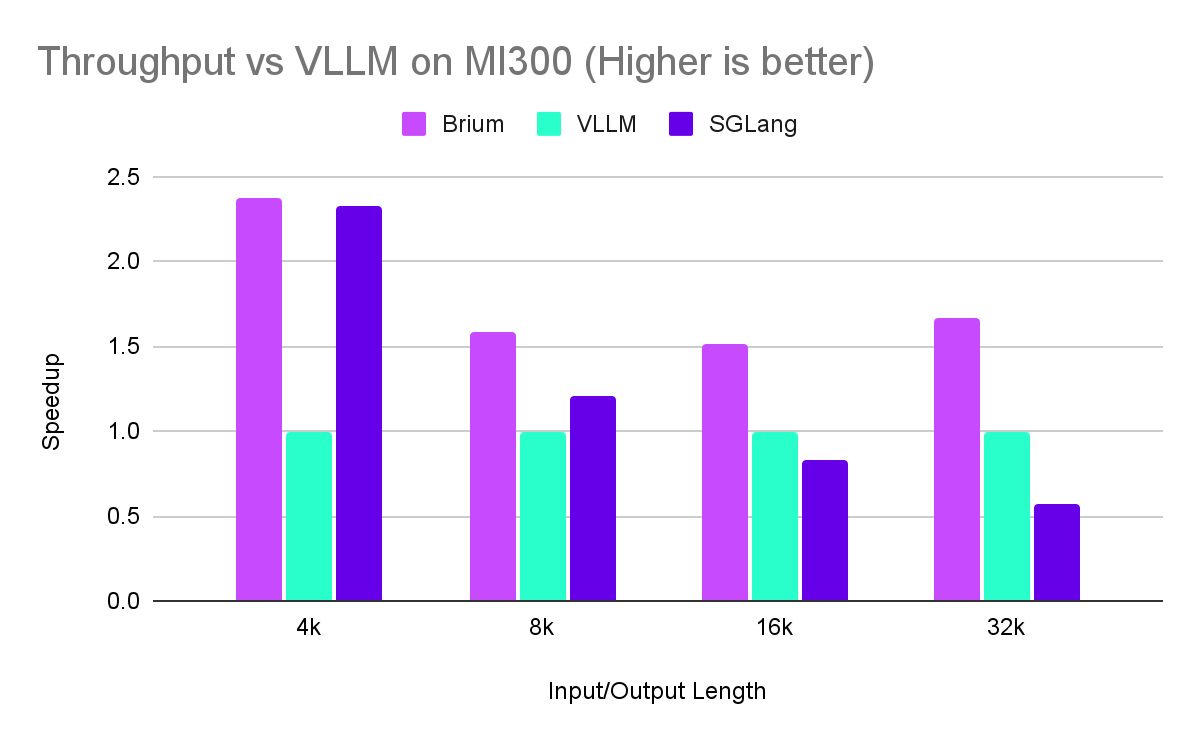
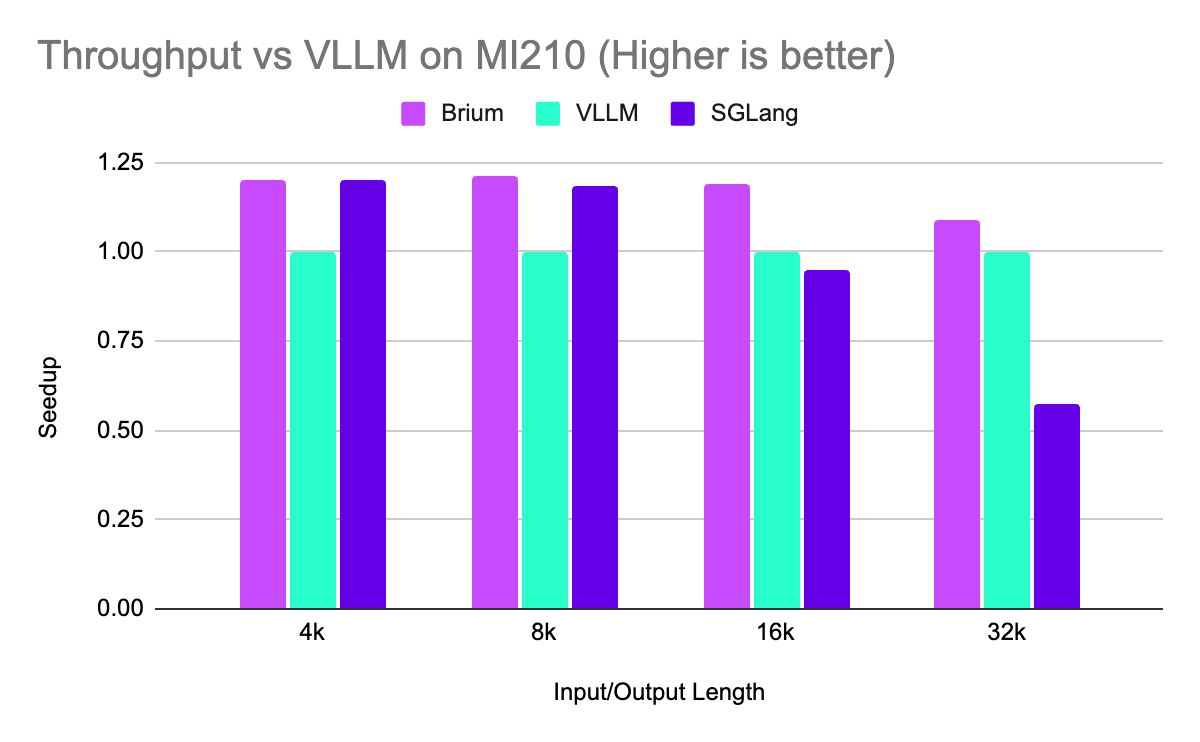
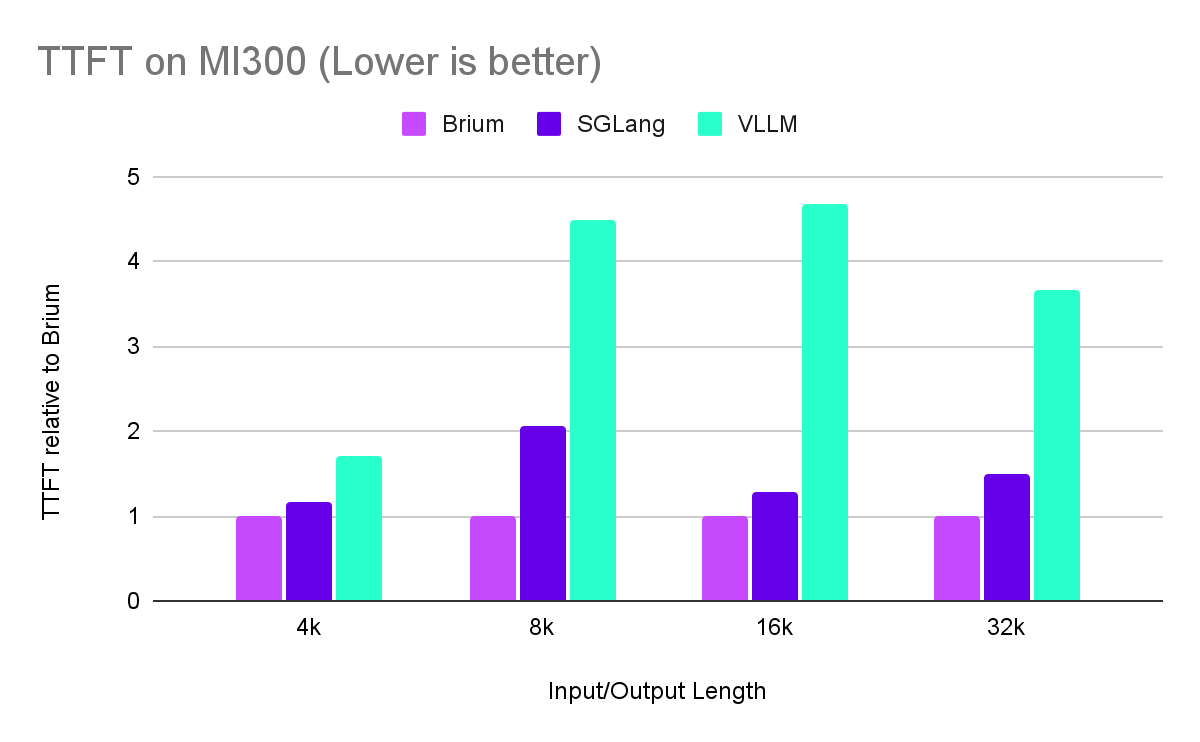
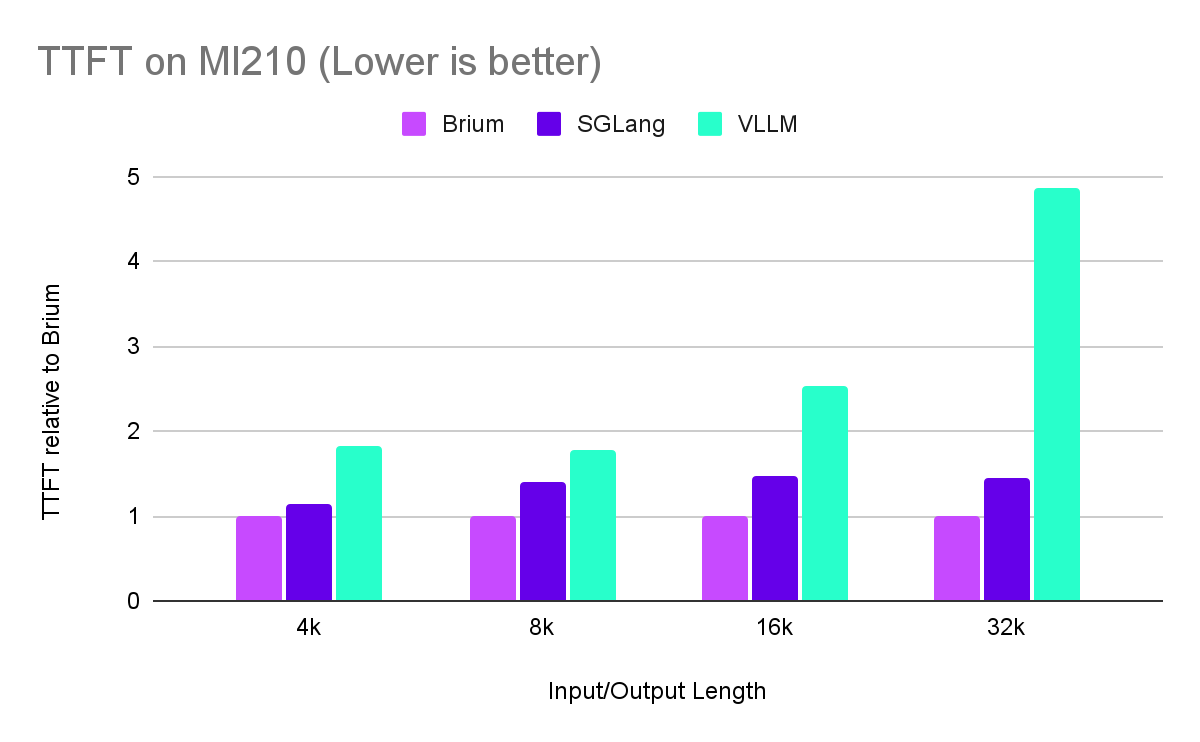
Note: We collected benchmarking data via scripts in sglang’s repository (bench_serving.py) by having an OpenAI_API server serving the requests in each case. Inputs were served in a deterministic manner all at once (measuring offline capabilities). We normalize settings across all frameworks to make comparisons fair including disabling prefix caching, setting the same prefill chunking size, no quantization, no compression of any kind.
Through our efforts, we have attained cutting-edge performance in both throughput and Time To First Token. This translates to improved return on investment (ROI) on hardware, with the potential to minimize total cost of ownership (TCO) by reducing the number of GPUs necessary to achieve the same outcome.
Additionally, these advancements could unlock the future of AI applications, opening the door to novel use cases.
Conclusion
We briefly looked at offline serving to highlight GPU execution optimizations. We hope to share more interesting results over the coming weeks.
Stay tuned as we continue pushing the boundaries of LLM inference on diverse hardware platforms!
Contact Us for more information at contact@brium.ai
~Brium Team